

Lei Chen , PhD candidate
Tsinghua University, Beijing 10084, China
Birthday 1989-12-07
Tel: +86 136 2207 2788
Email: chen_lei@tju.edu.cn
Education


Aug. 2009 - Jul. 2013 ,School of Electronic and Information Engineering, Tianjin University
Aug. 2013 - Jan. 2016 ,School of Electronic and Information Engineering, Tianjin University
Feb. 2016 - Jul. 2019 (Expected),Department of Automation, Tsinghua University
Research Project
Part-Activated Deep Reinforcement Learning for Action Prediction
In this paper, we propose a part-activated deep reinforcement learning (PA-DRL) method for action prediction. Most existing methods for action prediction utilize the evolution of whole frames to model actions, which cannot avoid the noise of the current action, especially in the early prediction. Moreover, the loss of structural information of human body diminishes the capacity of features to describe actions. To address this, we design the PA-DRL to exploit the structure of the human body by extracting skeleton proposals under a deep reinforcement learning framework. Specifically, we extract features from different parts of the human body individually and activate the action-related parts in features to enhance the representation. Our method not only exploits the structure information of the human body, but also considers the saliency part for expressing actions. We evaluate our method on three popular action prediction datasets: UT-Interaction, BIT-Interaction and UCF101. Our experimental results demonstrate that our method achieves the performance with state-of-the-arts.
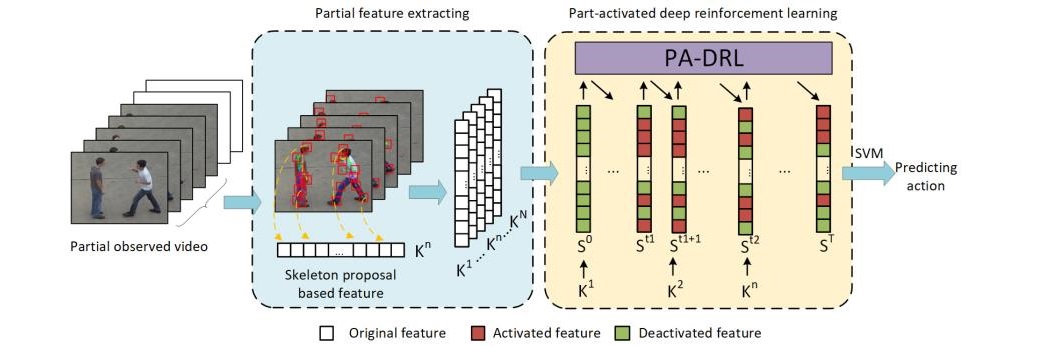
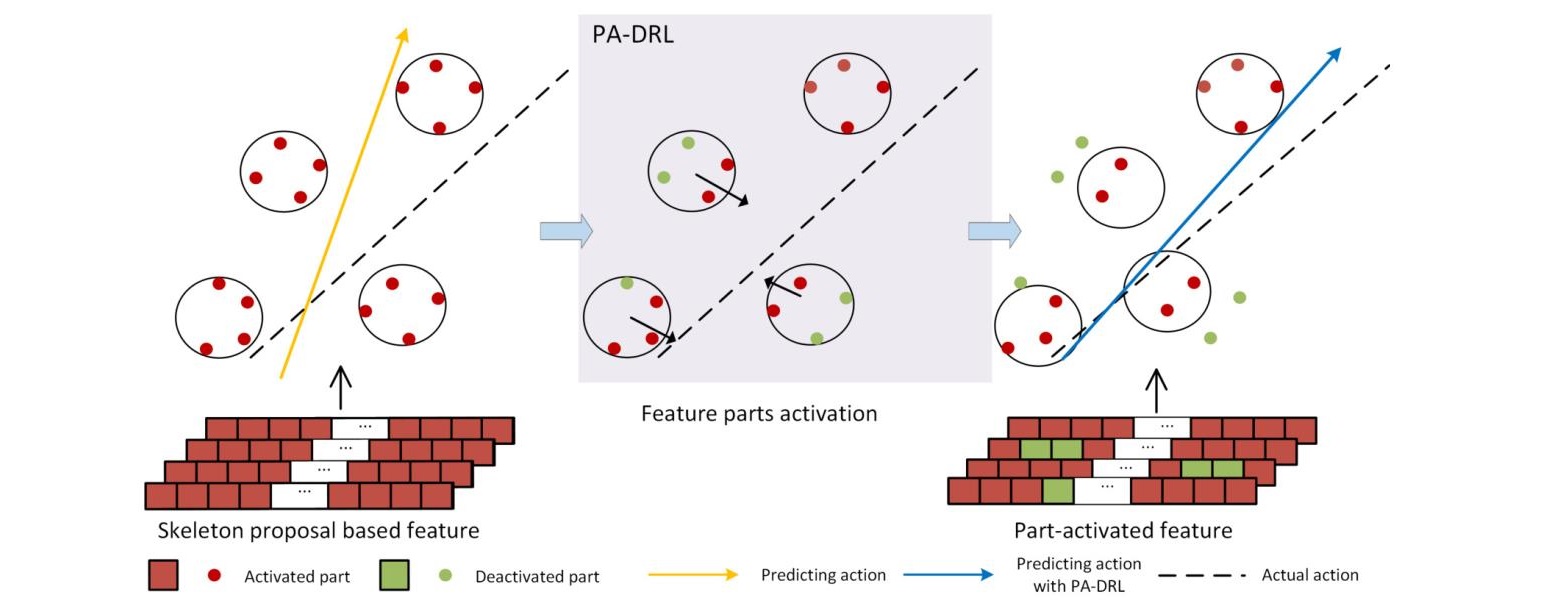
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Learning Principal Orientations and Residual Descriptor for Action Recognition
In this paper, we propose an unsupervised representation method to learn principal orientations and residual descriptor (PORD) for action recognition. Our PORD aims to learn the statistic principal orientations and to represent the local features of action videos with residual values. The existing hand-crafted feature based methods require high prior knowledge and lack of the ability to represent the distribution of features of the dataset. Most of the deep learned feature based methods are data adaptive, but they do not consider the projection orientations of features nor the loss of locally aggregated descriptors of the quantization. We propose a method of principal orientations and residual descriptor considering that the principal orientations reflect the distribution of local features in the dataset and the residual of projection contains discriminative information of local features. Moreover, we propose a multi-modality PORD method by reducing the modality gap of the RGB channels and the depth channel at the feature level to make our method applicable to RGB-D action recognition. To evaluate the performance, we conduct experiments on five challenging action datasets: Hollywood2, UCF101, HMDB51, MSRDaily, and MSR-Pair. The results show that our method is competitive with the state-of-the-art methods.
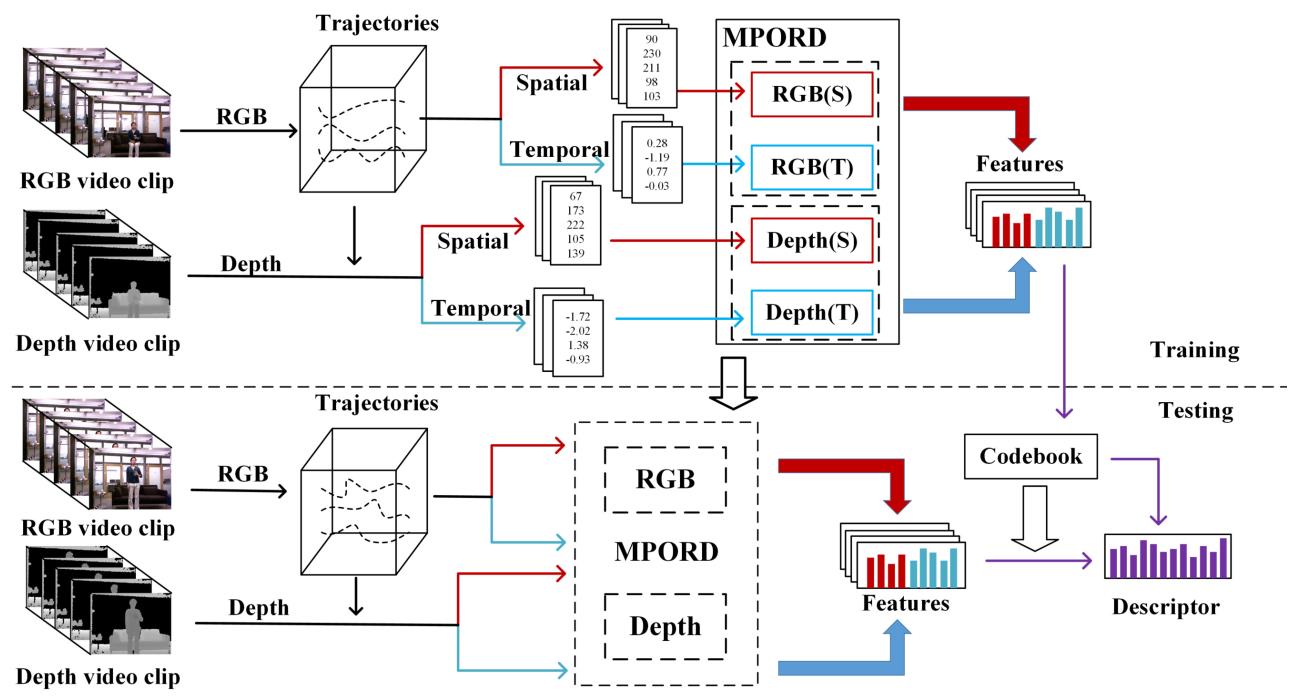
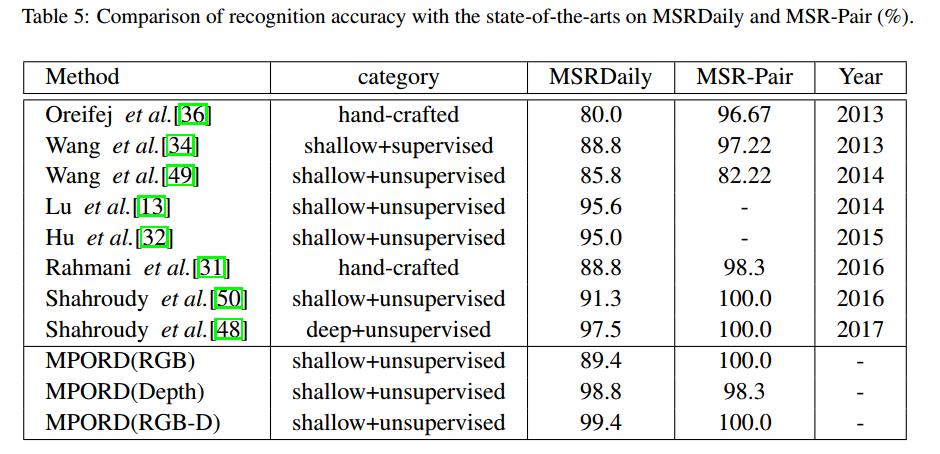
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
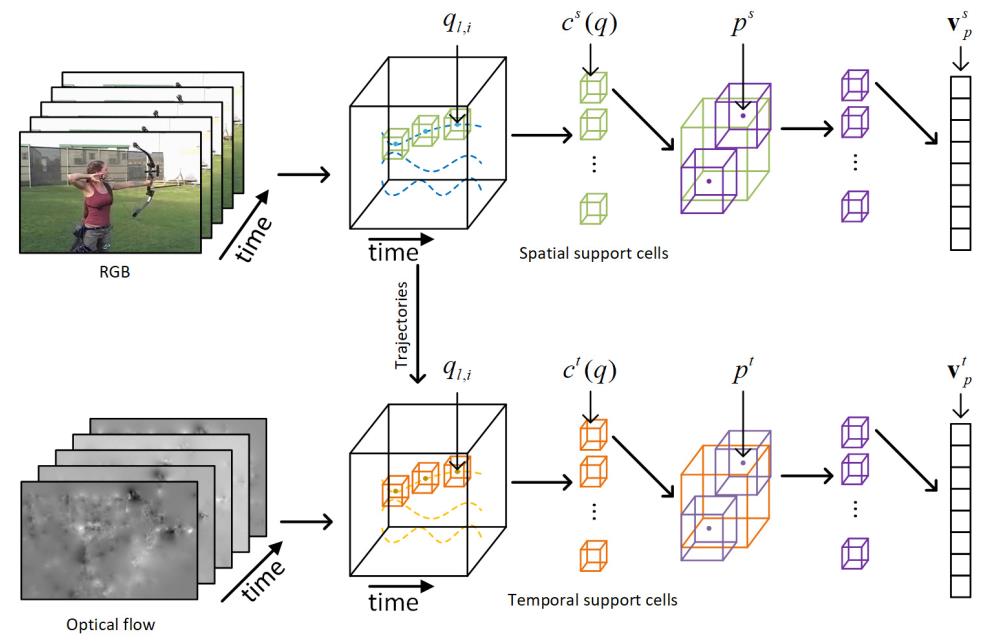
Learning Principal Orientations Descriptor for Action Recognition
In this paper, we propose an unsupervised learning based representation method, named principal orientations descriptor (POD), to describe the local and statistic characteristics for action recognition. Unlike hand-crafted features which require high prior knowledge, our POD is learned from raw pixels and reflects the distribution of principal orientations. Different from deep learning based features which is limited by a large number of labeled data,our POD is learned in an unsupervised learning manner. We learn POD in the spatial domain and the temporal domain individually, which makes POD share the advantages of both the spatial and the temporal characteristics of a moving region. To evaluate the performance of POD, we conduct experiments on two challenging action datasets: Hollywood2 and HMDB51. The results show that our method is competitive to the existing methods.
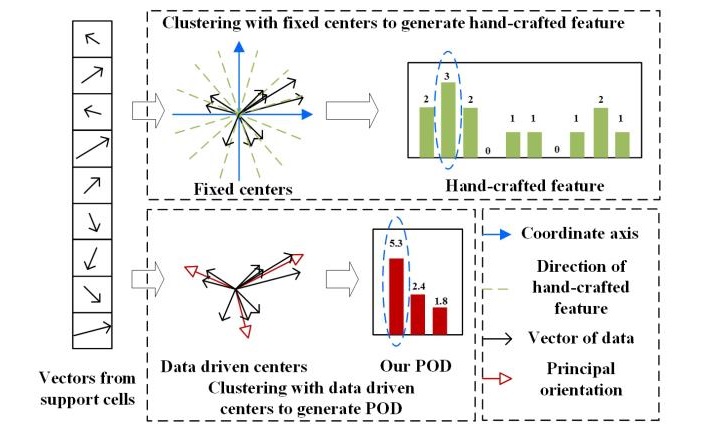
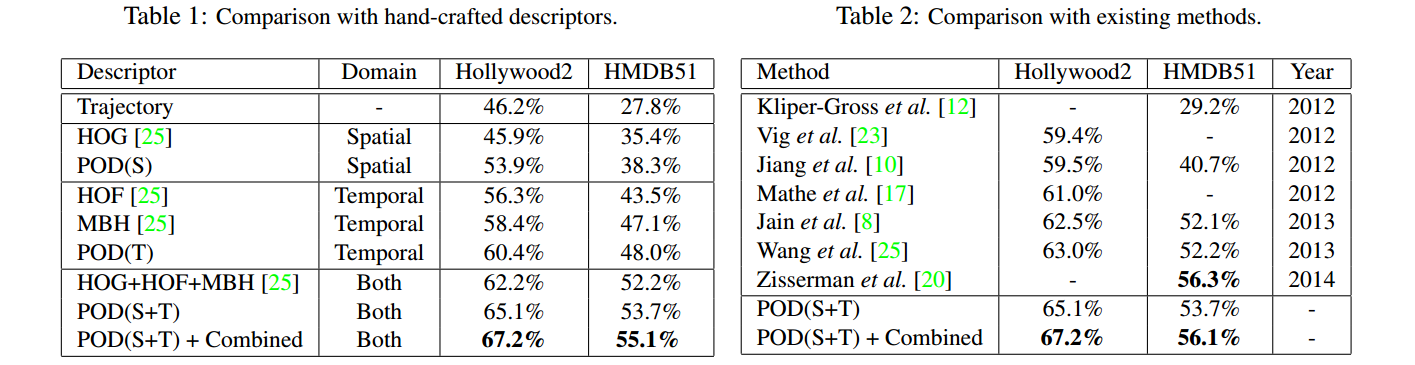
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Publication
1.Lei Chen, Zhanjie Song, Jiwen Lu, Jie Zhou. Part-Activated Deep Reinforcement Learning for Action Prediction. ECCV. 2018.
2.Lei Chen, Zhanjie Song, Jiwen Lu, Jie Zhou. Learning Principal Orientations and Residual Descriptor for Action Recognition. PR. 2018.
3.Lei Chen, Zhanjie Song, Jiwen Lu, Jie Zhou. Learning Principal Orientations Descriptor for Action Recognition. ACPR. 2017.
4.侯春萍, 陈磊, 王晓燕,等. 自由立体显示的自适应图像合成算法[J]. 华南理工大学学报:自然科学版, 2015(9):100-106.
国家发明专利:《基于裸眼3D显示技术的合成算法》,发明专利号:ZL201210255840.3 ,发明人名称:侯春萍,王晓燕,陈磊
国际专利:《基于振动光栅的裸眼立体显示方法与装置》,申请号:PCT/CN2014/078686 (参与)