
THU-READ: Tsinghua University RGB-D Egocentric Action Dataset
Abstract
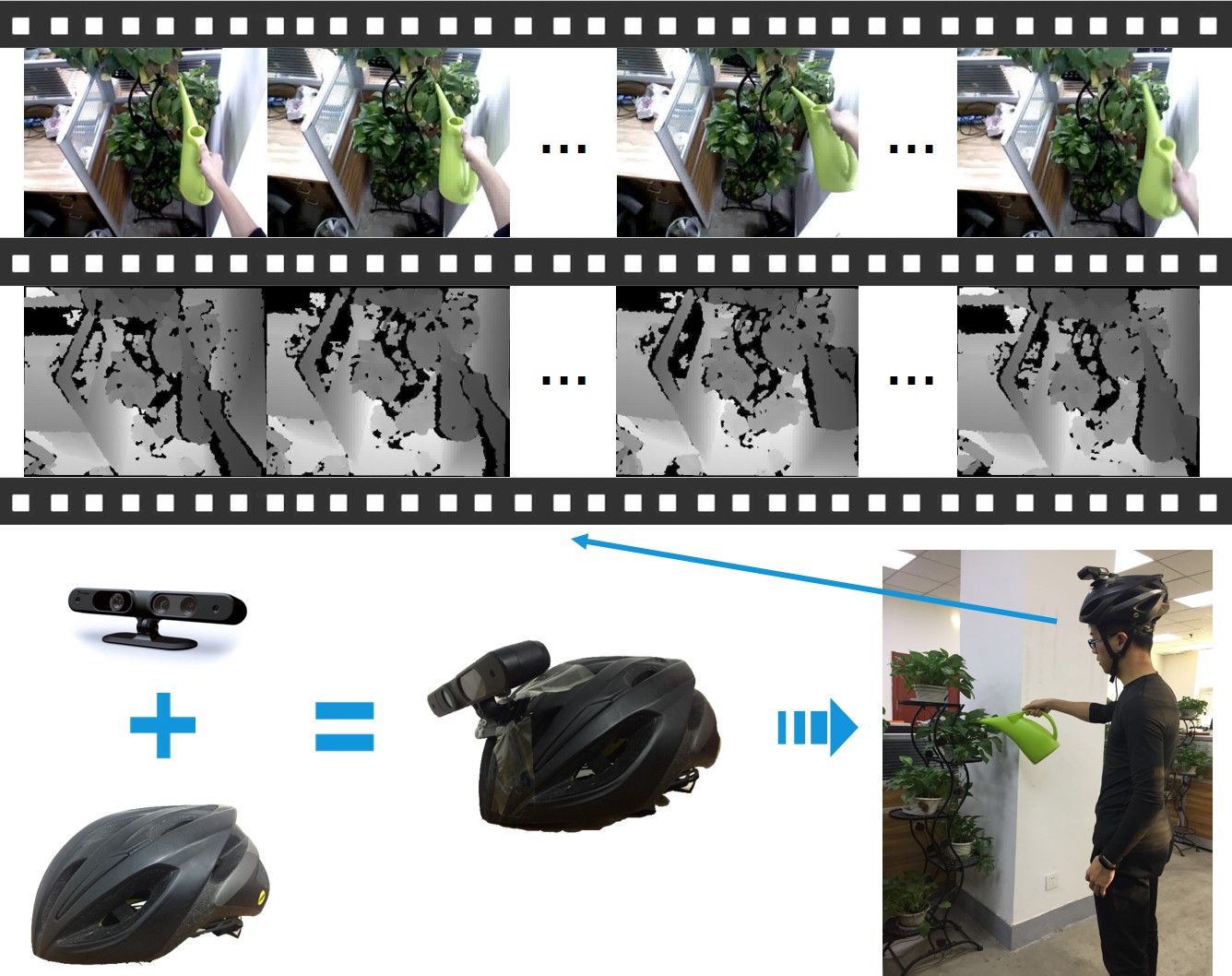
THU-READ is an RGB-D dataset collected in Tsinghua University for action recognition in egocentric videos. The dataset contains 40 action classes, which are “all-about-hand”. In order to balance the data distribution, we asked 8 subjects (6 males and 2 females, height ranging from 162 cm to 185 cm) to repeat performing the action of each class for the same N times (here we chose N = 3). Finally, we obtained 1920 video clips, where 1920 = 8(subjects)*2(modalities)*40*(classes)*3(times).
Data collection method
We mounted an RGB-D sensor on a helmet, which was placed on the subject's head. For the purpose of acquiring egocentric action videos, we kept the camera in the same direction with the subject's eyesight so as to simulate the real conditions.
Download
You are free to download the dataset for non-commercial research and educational purposes.GoogleDrive: Depth, RGBD1, RGBD2, Anno.
BaiduYun: Depth, RGBD1, RGBD2, Anno.
Reference
Research papers that used this database should cite the following paper:Yansong Tang, Zian Wang, Jiwen Lu, Jianjiang Feng, and Jie Zhou, “Multi-stream Deep Neural Networks for RGB-D egocentric Action Recognition”, T-CSVT, 2019
Yansong Tang, Yi Tian, Jiwen Lu, Jianjiang Feng, and Jie Zhou, "Action Recognition in RGB-D Egocentric Videos", in ICIP, Sep. 2017, Beijing.Acknowledgment
We would like to thank Honghui Liu, Guangyi Chen, Shan Gu, Ziyan Li, Yaoyao Wu, Weixiang Chen and Jianwei Feng for dataset collection, and thank Prof. Song-Chun Zhu, Dr. Tianfu Wu and Yang Liu from VCLA, UCLA for valuable discussions.